
正規表現とは、正規文字列の規則を簡略して表現することをいいます。
例えば、次のような規則があるとします。
- 「a」を1個以上書く
- 「a」の後に「b」を3個書く
- 「b」の後に「c」を偶数個書く
- 最後に「d」または「e」を書く
この規則にしたがって文字列を作るとしたら「aaaabbbccccd」や「aaabbbcccccce」のようになります。
このように一連の規則にしたがって生成される文字列のことを正規文字列といい、その規則を記号を使って簡略化したものが正規表現です。
先ほどの規則を正規表現で表すと次のようになります。
よく使われる正規表現の記号
全部ではありませんが、pythonでよく使われる正規表現の記号には以下のようなものがあります。
| 記号 | 意味 | 例 | 合致する文字列 |
|---|---|---|---|
| * | 先行する文字、部分式、角括弧文字の0個以上と合致 | a*b* | aaaaaaaa, aaabbbbb, bbbbbb |
| + | 先行する文字、部分式、角括弧文字の1個以上と合致 | a+b+ | aaaaaaaab, aaabbbbb, abbbbbb |
| [] | 角括弧内の任意の文字(すなわち、「この中からどれでも」)と合致 | [A-Z]* | APPLE, CAPITALS, QWERTY |
| () | まとめた部分式(正規表現の「演算順序」で最初に評価される) | (a*b)* | aaabaab, abaaab, ababaaaaab |
| {m,n} | 先行する文字、部分式、角括弧文字をm個からn個(両端含む)と合致 | a{2,3}b{2,3} | aabbb, aaabbb, aabb |
| [^] | 角括弧にない文字と合致 | [^A-Z]* | apple, lowercase, qwerty |
| | | 「|」で区切られた文字や部分式のどちらかに合致(縦棒、または「バイブ記号」で大文字の「i」ではないことに注意) | b(a|i|e)d | bad, bid, bed |
| . | 任意の1文字(記号、数字、空白などを含む)と合致 | b.d | bad, bzd, b$d, b d |
| ^ | 文字または部分式が文字列の先頭にあることを示す | ^a | apple, asdf, a |
| \ | エスケープ文字(「特別な」文字を字面で使うことができる) | \^\|\\ | ^|\ |
| $ | 正規表現の末尾として使う。「文字列の終わりまでこれと合致」を意味する。これがないと、すべての正規表現はデファクトで「.*」を末尾に持ち、文字列の先頭部分と合致することを意味する。これは、^記号と同様なものと考えてよい。 | [A-Z]*[a-z]*$ | ABCabc, zzzyx, Bob |
| ?! | 「含まない。」この珍しい記号対は、その直後の文字(または正規表現)が、より大きな文字列のその位置に現れるべきではないことを意味する。これは使い方が難しい。その文字が文字列の他の部分に現れるかもしれないからだ。文字が一切現れないようにするには、^と$とを両端に組み合わせて使う。 | ^((?![A-Z]).)*$ | no-caps-here, $ymb0ls a4e f!ne |
正規表現を使ってスクレイピング
正規表現はスクレイピングするときにも役に立ちます。
例えば、当サイトのトップページから記事一覧の中からアイキャッチ画像のURLを取り出したい場合。次のようにfind_all()を使って取り出したとします。
from bs4 import BeautifulSoup
html = urlopen(‘https://kubogen.com/’)
bs = BeautifulSoup(html, ‘html.parser’)
images = bs.find_all(‘img’)
for image in images:
print(image[‘src’])
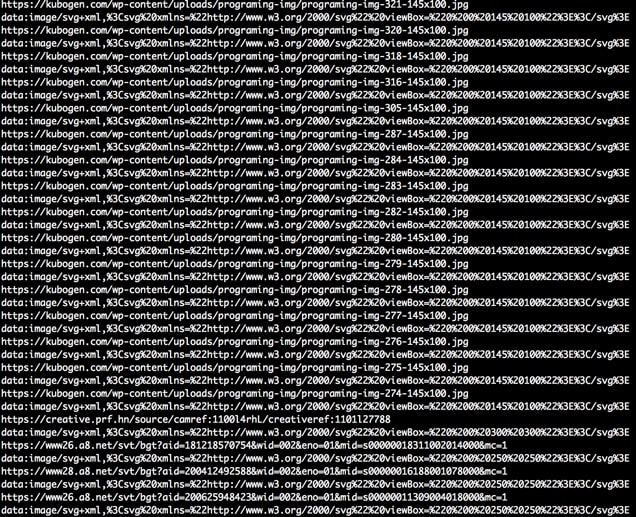
期待したものだけでなく、色々と無駄な要素も出力されてしまいました。
このサイトはロゴに画像ではなくテキストを使っていますが、もし画像を使っていた場合、先ほどのコードだとロゴ画像も取り出されてしまいます。
そこで、正規表現を使ってアイキャッチ画像のパスだけ取り出すために、以下のようにします。
from bs4 import BeautifulSoup
import re
html = urlopen(‘https://kubogen.com/’)
bs = BeautifulSoup(html, ‘html.parser’)
images = bs.find_all(‘img’, {‘src’:re.compile(‘..\/wp-content\/uploads\/programing-img\/programing-img-.*.jpg’)})
for image in images:
print(image[‘src’])
正規表現モジュールのreをインポートし、正規表現パターンをコンパイルしています。
最初のコードと違うのは、find_all()の中身。これは画像パスの先頭が「../wp-content/uploads/programing-img/programing-img-」、末尾が「.jpg」の画像パスだけを出力するように正規表現で指定しています。
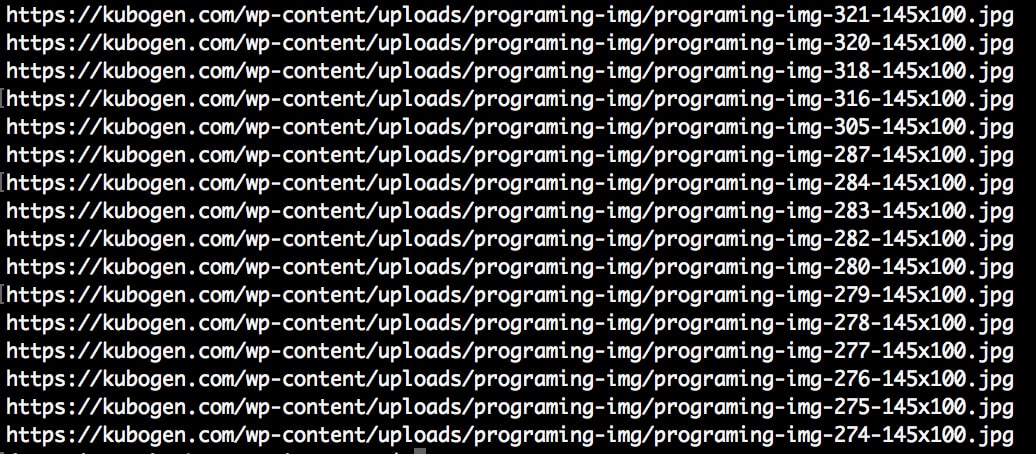
正規表現を使うことで目的のアイキャッチ画像のパスだけを出力できました。
このように何らかの規則を見つけて、その規則を正規表現で指定することで、目的の要素をより正確に取り出すことが可能です。

![]()
Leave a Comment